Data Science on Firesquads: Classifying Emails with Naive Bayes
At Hudl, each squad on the product team takes two weeks each year to help out the coach relations team in an ongoing rotation known as Firesquads. This year, for Firesquads, the data science squad built a Naive Bayes classifier to automate the task of categorizing emails.
Data Science on Firesquads: Classifying Emails with Naive Bayes
At Hudl, each squad on the product team takes two weeks each year to help out the coach relations team in an ongoing rotation known as Firesquads. This year, for Firesquads, the data science squad built a Naive Bayes classifier to automate the task of categorizing emails.
At Hudl, we take great pride in our Coach Relations team and the world-class support they provide for our customers. To help them out and to foster communication between the product team and Coach Relations, we have an ongoing rotation known as Firesquad. Each squad on the product team takes a two-week Firesquad rotation, during which we build tools and fix bugs that will help Coach Relations provide support more efficiently and more painlessly.
Introduction
This year, for our Firesquad rotation, we on the Data Science squad wanted to help automate the classification of support emails. The short-term goal was to reduce the time Coach Relations needs to spend when answering emails. Longer term, this tool could allow us to automatically detect patterns and raise alarms when specific support requests are occurring at an abnormal rate.
Road-mapping
At a practical level, we had two challenges to solve:
- Train an effective classifier.
- Build an infrastructure that reads emails from Zendesk, classifies them, and writes those classifications back to Zendesk.
In order to solve these challenges, we used the following technologies.
Modeling: Apache Spark’s MLlib
Although there are many machine learning implementations that could be used to classify emails, few of them can train on large datasets as efficiently as Apache Spark’s MLlib. Given the large number of emails in our training sample and the even larger number of features that we anticipate using, the choice of MLlib was quite natural.
Data Pipeline: Amazon’s Kinesis
Amazon Kinesis is a cloud-based service for processing and streaming data at a large scale. Although we do not currently have a large influx of support emails that would necessitate such a solution, we decided to use Amazon’s Kinesis because of it’s scalability and the ease of use. In addition, learning to use Kinesis would level up our team for processing large scale data in real time.
The Classifier
The task of classifying emails is not a new one. Spam filters are a classic example of this task. Rather than reinvent the wheel, we decided to use a tried and true approach: a Naive Bayes classifier using word n-grams as features.
Naive Bayes
Bayes theorem (shown below), indicates that the probability that a certain email is of class C_k given that it has a certain set of features: x_1, ..., x_n is proportional to the likelihood of that class (how often that class occurs in all the emails) times the probability of those features occurring in an email given that an email is class C_k divided by the probability of those features occurring.
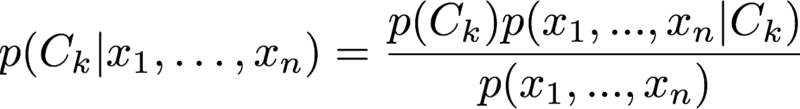
Using the chain rule allows us to rewrite Bayes theorem as:
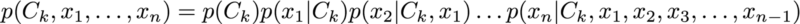
We’re unlikely to have any way to estimate these complex conditional probabilities, so we make the Naive assumption that features are conditionally independent:
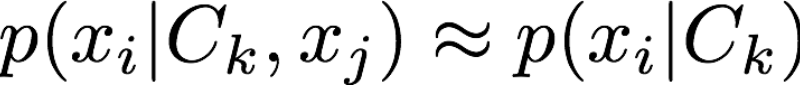
This makes the problem much more tractable and allows us to simplify the initial classification probability to the product of simple single feature conditional probabilities as shown below:
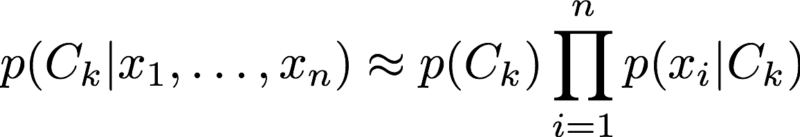
Data
To start, we exported all email data from Zendesk from 2012 to 2015. After removing unlabeled emails or emails with out of date labels, we have 150,000 emails to use in building and evaluating the model. 80% of these emails are used to train the model while 20% are reserved as a test set for performance evaluation.
Model
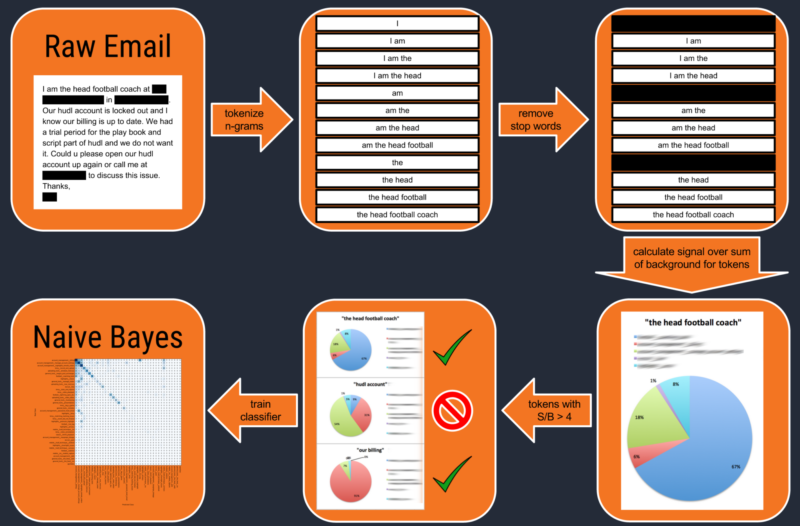
A flowchart showing the steps we took to build the classifier is seen above. We first tokenize each email by creating n-grams of one, two, three, four, and five words. After this, we removed all “stop words” such as “the” or “and.” To find out which tokens are most important for differentiating between different categories, we went through each email category and calculated the signal to background (S/B) ratio. The S/B ratio for a given category and token is defined as the number of emails containing that token that are in the category divided by the number of emails containing that token that are not in that category. For a specific category, call it A, this can be written: P(A | token)/(1 - P(A | token)). We want the S/B ratio to be fairly high so that we will use tokens that have a strong discriminating power, in our case we require S/B > 4.
Test Set Performance
The classifier was trained with Apache Spark MLlib’s implementation of a Naive Bayes classifier. The training sample consisted of 80% of the emails. The overall accuracy of the classifier was evaluated using the remaining 20% of emails that had been reserved as a test set. This accuracy was found to be 87.9% on the test set. The confusion matrix for the entire test set is displayed below.

As you can see, the classifier performs very well on the top labels but very poorly on any labels that do not have many examples. This is largely due to the fact that there is not enough data to discriminate between the features of these low-occupancy emails. The existence of so many low-occupancy email categories is largely due to the fact that the email labeling used in Zendesk has been updated recently for certain labels. With future data, the classifier can be retrained and its performance on many labels should improve dramatically.
Systematic Uncertainties
Although our classifier performs well on the 20% test set, this test set is not, in fact, representative of the current label distribution. The distribution of the top five labels over time is shown below:
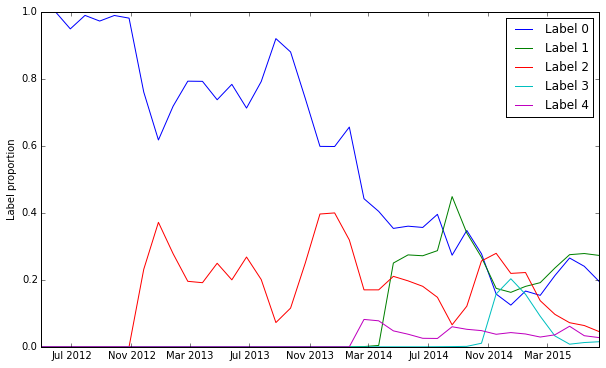
To see how this changing label distribution would affect the accuracy, we calculate the accuracy for a given month by multiplying the precision for each label by the number of emails with that label and dividing by the total number of emails in that month. Mathematically, this is represented by the following equation:
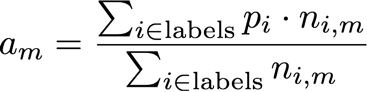
Where a_m is the accuracy for month m, p_i is the precision for label i and n_{i,m} is the number of emails in month m for label i. The figure below shows the distribution of calculated accuracies for each month in 2014 and 2015.
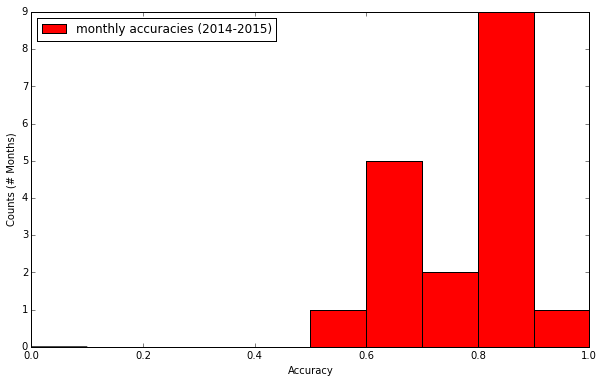
We expect that the mean of these accuracies will be similar to the mean we will see in the future when this classifier is put into production. In addition, we can calculate our systematic uncertainty on this mean by finding the difference between this mean and the 34.1% and 65.9% quartiles. This gives us an expected accuracy of: 75.6% +5.8%/-6.8%.
Deployment
As mentioned previously, we chose to implement this classifier with the combination of Apache Spark’s MLlib and Amazon’s Kinesis. The use of both of these tools in tandem allows us to effortlessly scale the pipeline to handle widely varying loads.
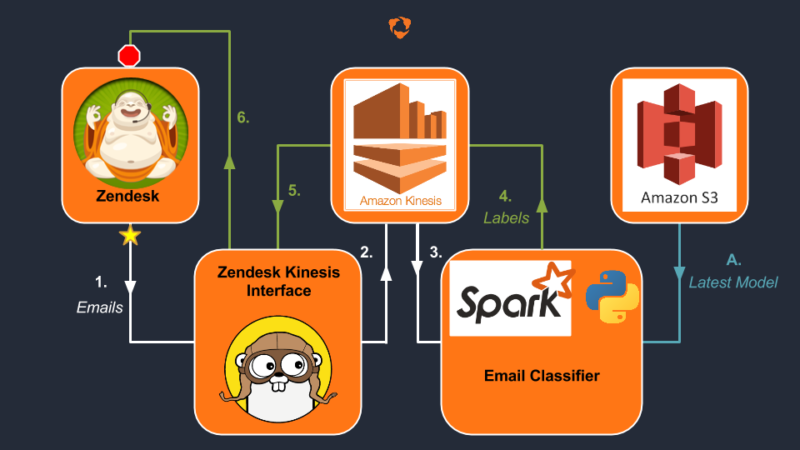
The data pipeline consists of six principal steps, shown in the above flowchart:
- Emails collected by Zendesk are batched and JSON-formatted by our Zendesk/Kinesis Interface, written in Google’s Go language.
- The Zendesk/Kinesis Interface then implements a Kinesis Producer and publishes the email records to the input Kinesis shard.
- The Email Classifier, having loaded the latest model from Amazon’s S3 [A.], connects to the input shard and reads the latest records. It then formats the emails into a Spark RDD and classifies them in parallel.
- With the emails classified, the Spark job formats JSON records containing the email-ID and the predicted label. It batches these into 500 record batches and publishes them to a different, output Kinesis shard.
- The Zendesk/Kinesis Interface then recives these output records.
- With the labled emails, the Zendesk/Kinesis Interface then modifies the webmail form by pre-populating the category selection with the predicted label.
We can now scale this infrastructure by simply adding additional Kinesis shards when IO limited, or by adding Spark executors if processing becomes a bottleneck.
Finally, as time progresses and we recieve more emails and feedback from Coach Relations we can retrain the existing model, or create new models all together, and simply upload them to Amazon’s S3. The newest model is then selected and implemented automatically, allowing us to continually optimize and improve.
Conclusions and Next Steps
Moving forward, we would like to make improvements to the email classification performance so that the classifier can perform better on categories outside the top six. One way for us to do this is to gather more labeled email data and use it in training. We will gradually accumulate more labeled emails as time goes on and as the Coach Relations team answers more emails, so this one will occur naturally. A second way is to use a more advanced classification scheme that does not make the naive conditional independence assumption used by Naive Bayes. To this end, we have begun testing out some recurrent neural networks.
Stay tuned and if you want to help us build recurrent neural networks or other awesome classifiers, contact us!