Faster and Cheaper: How Hudl Saved 50% and Doubled Performance
We took time to optimize our EC2 instance types. By finding the maximum load a server could handle we were able to run a quarter as many app servers. Our hourly spend dropped by 50%. Despite the huge cost savings, we also saw a 2x improvement in response times! This came about by moving to a newer instance family.
Faster and Cheaper: How Hudl Saved 50% and Doubled Performance
We took time to optimize our EC2 instance types. By finding the maximum load a server could handle we were able to run a quarter as many app servers. Our hourly spend dropped by 50%. Despite the huge cost savings, we also saw a 2x improvement in response times! This came about by moving to a newer instance family.
Hudl has been running on Amazon Web Services (AWS) for years and we rarely take the opportunity to optimize our instance types. Recently we began moving to Virtual Private Cloud (VPC), which caused us to re-examine each instance type we use. Choosing the right instance type from the start is challenging. It’s tough to choose the optimal instance type until you have customers and established traffic patterns. AWS innovates rapidly, so today there are a lot of choices. Balancing compute and memory, durability and performance of storage, and the right type of networking attributes is important. Choose wrongly, and you’ve wasted money, incurred downtime, and/or hurt performance. Spend too much time optimizing and you may have traded time better spent on product improvements and revenue in exchange for a relatively small amount of money.
In this blog post I describe how we shaved 50% off our AWS spend for web servers and doubled performance. We also learned about how different instance types perform relative to each other.
Goals
- We wanted to understand how much traffic one server could handle.
- Once we understood max load, we could make a better apples-to-apples comparison of different EC2 instance types and figure out the optimal one for our usage.
- Thinking about auto-scaling, we wanted to understand an appropriate metric (CPU, requests per second, something else?) to trigger scaling events.
Approach
A common challenge for conducting load tests is coming up with accurate test data. It can be time-consuming to generate the test data and you still only get an approximation of reality. You don’t want to optimize for a traffic pattern that won’t actually occur in production. Rather than simulate production traffic, our tooling allowed us to safely use production traffic for these tests. In addition to more accurate results, we saved a lot of time. This entire effort was done with just one day of work.
To use production traffic for this test, we relied on a characteristic of the Elastic Load Balancer (ELB) service and some of our own internal tooling. All of our web traffic initially flows into our ELB. The ELB divvies traffic up evenly across our nginx instances. Nginx is aware of our various services and will choose the appropriate app instance for that request.
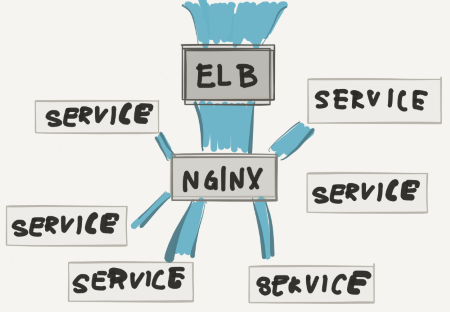
Because we run in AWS and we care about high availability, we run servers in triplicate by running in multiple availability zones (AZ). Side note: if you aren’t familiar with the idea behind availability zones, watch this (~6min), it’s pretty cool stuff. To maximize performance and isolate problems, we like to keep traffic within the same AZ. We think of an AZ as a separate data center, so it makes sense not to hop back and forth between data centers while servicing each request.
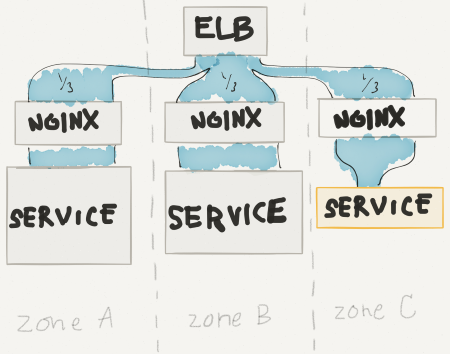
By reducing the number of servers available in one AZ, that became our Test set. Because the ELB would continue to divvy up traffic evenly across all three zones, the other two were completely unaffected and became our Control set. By reducing the number of servers in the Test set we could gradually increase the amount of traffic handled by each server. We monitored performance for signs of degradation. Once we began to observe degraded service, bingo, we knew the maximum load.
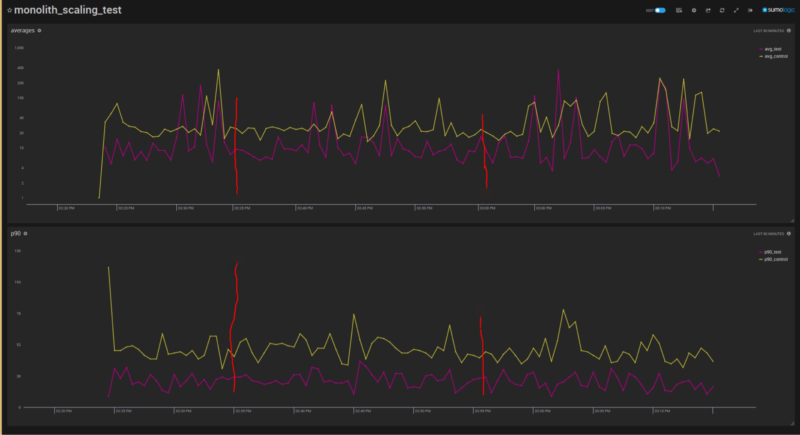
As we continued to shed servers in the Test set, we also kept an eye on CPU utilization. By incrementally ratcheting up traffic, we could observe the CPU characteristics at maximum load. You can see the impact to CPU after we increased the amount of traffic (the two green lines) vs the CPU of a server in the control AZ. Instance IDs blurred to protect the innocent.
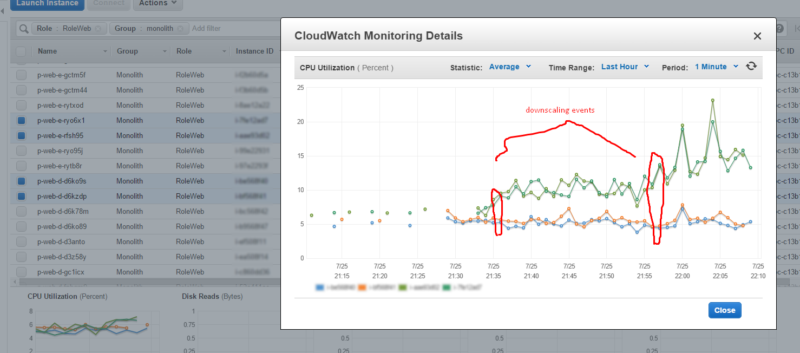
We repeated this same test with a few different instance types to find the sweet spot for us. The service under test was our oldest in our infrastructure and was running on m1.large instances. We finally landed on c4.xlarge and found, not only could we cut our hourly spend in half, but performance actually improved by 2x! The performance improvement was an unexpected bonus.
Takeaways
- After testing a few different instance types and finding the maximum load a server could handle we were able to run a quarter as many app servers. Our hourly (non-reserved) spend dropped by 50%.
- Despite the huge cost savings, we also saw a 2x improvement in response times! This came about by getting onto the newer instance family. In our case, this was a move from the m1 to the c4 family.
- Something we observed (and it would be sweet if Amazon made it clearer) is that compute, or Cores, are not apples-to-apples across instance families. Within a family, the 2x, 4x, 8x instances are apples-to-apples. The m4.4xlarge is pretty much twice as fast as the m4.2xlarge. But, the two cores on the m1.large are much slower than the two cores on a c4.large. Some of these instance families are pretty old, the M1 family was released in 2007, a good default is to always choose the most recent generation.
- Amazon has excellent details about instance types online, but they make it nearly impossible to easily compare them. Luckily, there are a number of sites available for just this purpose. I enjoy ec2instances.info.
- While testing another service, we observed a single c4.xlarge instance (16 ECU) handle the same load that 21 m3.medium (3 ECU). And, it was running around 12% CPU utilization vs the 25 – 30% on the m3.mediums! Oh, and response times went down, once again, by half!
- We found that performance began to suffer at around 40 – 50% average CPU utilization. At Hudl, we want to be able to lose an entire AZ (one third of our capacity) at any time without degrading performance. Assuming 35% utilization is our max, we need to actually aim for 35% * ⅔, or around 23%. That way, in the event of an entire AZ failure, we can absorb that traffic into the other two and still maintain performance.
- Having the tooling and infrastructure in place to quickly route traffic made it easy to conduct this experiment with minimal risk to our users. We invest a lot of time and effort in our foundation. This is one of the many ways that investment pays off.
Interested in working on problems like this? We should talk.