Migrating Millions of Users in Broad Daylight
In August we migrated our core user data (around 5.5MM user records) from SQL Server to MongoDB. We moved the data during the daytime while still taking full production traffic, maintaining nearly 100% availability for reads and writes during the course of the migration. Our CPO fittingly described it as akin to “swapping out a couple of the plane’s engines while it’s flying at 10,000 feet.” I’d like to share our approach to the migration and some of the code we used to do it.
Migrating Millions of Users in Broad Daylight
In August we migrated our core user data (around 5.5MM user records) from SQL Server to MongoDB. We moved the data during the daytime while still taking full production traffic, maintaining nearly 100% availability for reads and writes during the course of the migration. Our CPO fittingly described it as akin to “swapping out a couple of the plane’s engines while it’s flying at 10,000 feet.” I’d like to share our approach to the migration and some of the code we used to do it.
In August we migrated our core user data (around 5.5MM user records) from SQL Server to MongoDB. The migration was part of an ongoing effort to reduce dependency on our monolithic SQL Server instance (which is a single point of failure for our web application), and also isolate data and operations within our system into smaller microservices.
The migration was a daunting task – our user data sees around 800 operations/second and is critical to most requests to our site. We moved the data during the daytime while still taking full production traffic, maintaining nearly 100% availability for reads and writes during the course of the migration. Our CPO fittingly described it as akin to “swapping out a couple of the plane’s engines while it’s flying at 10,000 feet.” I’d like to share our approach to the migration and some of the code we used to do it.
The Big Picture
Our user records have IDs that are numeric and sequential. Starting at ID 1, users are migrated in ranges of 1000 IDs at a time, moving sequentially upward through all user IDs (from 1 to about 5.5MM). The critical state during the migration is the “point” user ID. All reads and writes for user IDs below the point (i.e. migrated users) go to MongoDB; operations to unmigrated IDs above the point continue going to SQL.
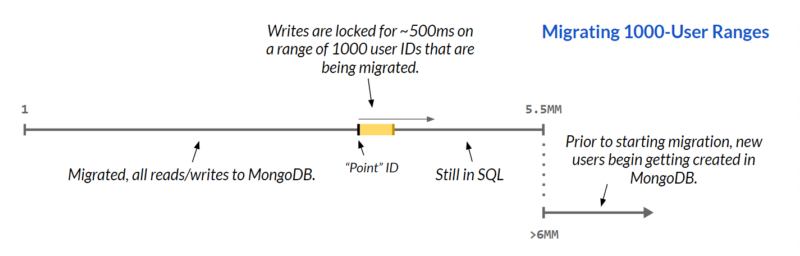
For the range being migrated (the point user ID + 999), write operations are locked; code along all write paths throws an exception if the write is for a user ID in the locked range. This guarantees that requests are never “lost” by sending writes for already-migrated users to SQL. Reads for the migrating range still go to SQL and return results, and all users in the migration range are considered “pending” until every record is completely migrated and the point user ID advances to the beginning of the next range. A batch of 1000 users takes about 500ms to migrate, so the probability of a write request colliding with a user being migrated is low.
Code Refactoring, Conditional Routing
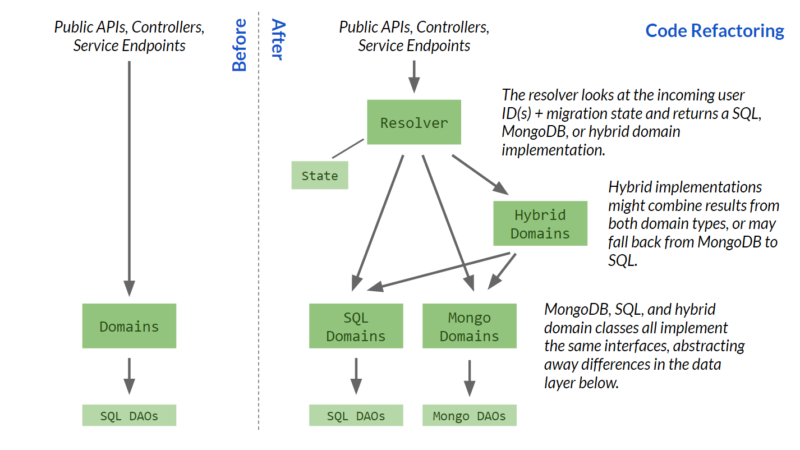
A lot of prep work went into refactoring application code to introduce conditional behavior that checks user IDs to see if they’ve been migrated or not, invoking SQL or MongoDB where appropriate.
Hudl’s web application code is multi-layer; it has a domain layer (with interfaces like IUserDomain and IUserUpdateDomain) that encapsulates business logic, validation, etc., and the domain implementations call a data layer of DAO classes that work directly with the database(s). Web/MVC components (e.g. controllers and service endpoints) sit above the domain layer. Refactoring this meant:
Introducing the new MongoDB data layer and domain code to support the same behavior as the existing SQL domains.
Adding a “Migration Resolver” (MigrationResolver.cs) that decides which domain implementation to return for the requested user ID(s), and re-routing all higher-layer code (e.g. controllers, APIs, etc.) through the resolver instead of (the previous behavior) directly interfacing with the domain layer.
Introducing a “Migration State” class (UserMigrationState.cs) as the source of truth about where the migration is at (i.e. the point user, and whether a batch is locked for migration).
Post-refactor, here are a few examples of how different user operations behaved:
GetUserById(123) — MigrationResolver.cs (line 118)
The resolver checks the state singleton for the provided user ID. If the user is migrated, the resolver returns the MongoDB domain; otherwise it returns the SQL domain.
GetUsersByIds({ 123, 456, 1200, 13457 }) — HybridUserLookupDomain.cs (line 60)
The resolver returns a hybrid domain that uses the state singleton to split requested IDs into migrated and unmigrated subsets, then querying the MongoDB domain for the former and SQL domain for the latter. Results from both are combined, sorted, and returned.
GetUserByEmail(“rob@example.com”) — HybridUserLookupDomain.cs (line 40)
The resolver returns a hybrid domain that queries MongoDB for the email first; if found, it’s returned, otherwise SQL is queried for the same email.
Consistent layering and vertical separation between SQL and MongoDB code really helped us. By guaranteeing that everything went through the resolver and that all of our SQL and MongoDB operations were isolated and separate, we could confidently know that we didn’t have stray SQL calls scattered throughout the code, reducing the potential that we missed or forgot one as we refactored and introduced our conditional routing. It helped when introducing migration-specific code like our write-lock behavior in just a few places, giving us confidence that we had everything covered. If you’re tackling a similar effort, consider some up-front work (independent of the migration effort itself) to improve your code layering if you don’t have it already.
The Migration Job
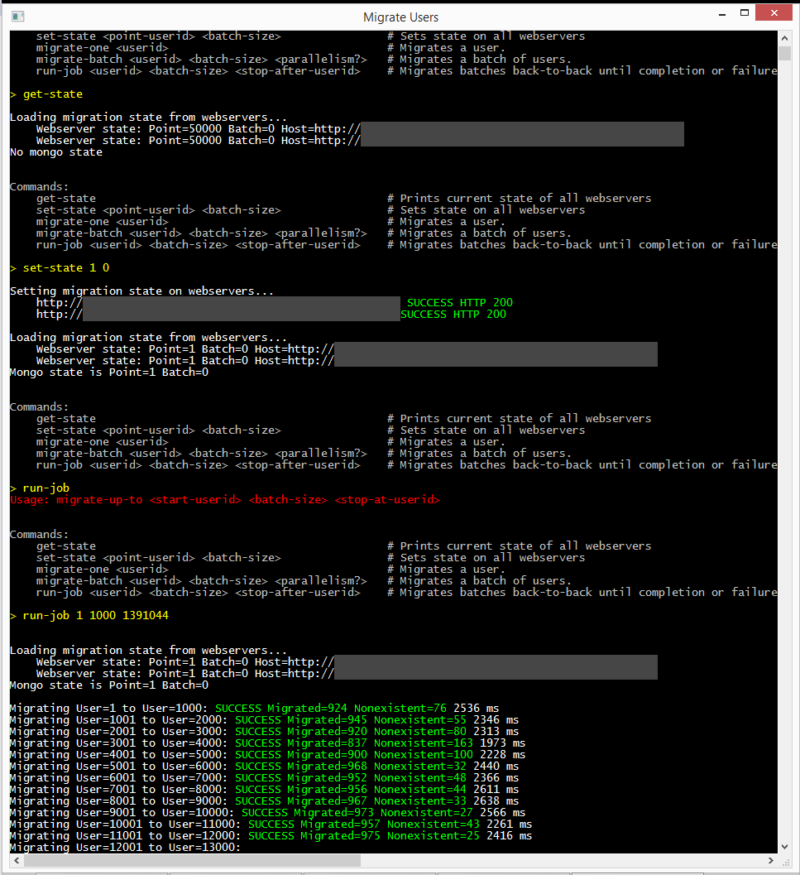
A custom, interactive console application (UserMigrationJob.cs) serves as the control process for the entire job. It provides commands to migrate single users or manual ranges for testing and gives clear output about migration state and success. It’s written to cautiously expect success – if it ever encounters a response or state that it’s unfamiliar with, it aborts the migration and leaves the system in a known, stable state, printing out diagnostic information to help fix the situation and resume after making corrections.
Here’s an early run of the job in our staging environment (the batches take a bit longer to migrate since our stage hardware is less powerful):
Our primary production webservers (about 20 c4.xlarge EC2 instances) serve as the workhorses for the migration; user ids are split into batches and parallelized across them. Using the webservers is convenient because they already have all of the code needed to interact with both SQL and MongoDB, so there’s no need to copy or duplicate data layer code to the job itself. It also makes it easy to parallelize the job, since it just means splitting a range of user IDs across all the servers.
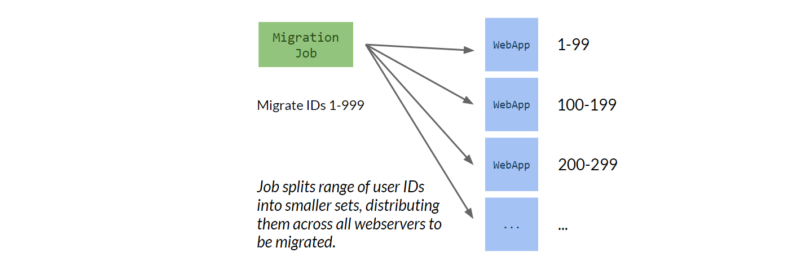
It does mean throwing some extra load at apps taking production traffic, but that’s mitigated by being prepared with our systems monitoring, logging, and our ability to throttle or stop the job if necessary.
The migration job itself starts at user ID 1 and works upward in batches of 1000. For an iteration migrating a range of users, it:
- Splits the batch into batch size / N webservers.
- Makes an HTTP request to set the migration state on each webserver, which sets the point user ID and locks writes for the entire range about to be migrated.
- Sends one sub-batch to each webserver. The webservers query the batch of users from SQL, insert them into MongoDB, and heavily verify the migration by re-querying both databases and comparing results. The webserver responds with a status and some result data.
- Makes an HTTP request to each webserver to move the point user ID and unlock the batch. The point is moved up to the next unmigrated user ID.
- Repeats.
If at any point a step fails or we don’t see a synchronous state across the servers, the job stops itself, abandons the current batch, unlocks writes, and echoes the current state for manual intervention.
Having the migration state mutable and stored in memory on the webservers makes the system a bit vulnerable. The state is critical for routing, and if it’s ever out of sync it means we’re potentially corrupting data by sending it to the wrong database. To mitigate this, the job persists the state to a database after each batch is migrated, and the webapps are coded to read the state on startup or prevent startup completely if they can’t. The job is also adamant about ensuring consistency of the state, preferring to keep it corrected and avoid continuing the migration if things aren’t as they should be.
Go Time
When everything was ready to go, we came in on a Monday morning and turned on the configuration toggle to start sending new user creation to MongoDB and let that simmer for a little while, keeping an eye on metrics and logs for anything unexpected. During this and the remainder of the migration, we were in close contact with our awesome support team’s tech leads – they were plugged in on where we were at, and were looking out for any odd support calls or behavior that trended with the ranges of IDs for new users or users that had been migrated.
We started the actual migration by moving users 1 – 9999 on Monday afternoon. Again moving cautiously, we monitored the systems for the rest of the day and overnight before committing to a larger-scale run.
On Tuesday morning we ran the migration on users 10000 – 99999. This longer, sustained run let us understand how the load of the migration would impact the webservers and databases we were working with. After pushing the migration up to user 499999, we stopped again to monitor and observe. We did uncover a couple minor bugs in our domain layer at this point, so we spent the remainder of the day coding, testing, and deploying those fixes.
Wednesday after lunch, we pulled the trigger and ran the migration on the remaining users, which took around an hour to complete. Nobody really even noticed we were migrating some of Hudl’s most critical data right out from under them; it was a typical Wednesday afternoon – and that’s exactly how we wanted it.
Wrapping Up, and a Few (of Many) Lessons Learned
After completing the migration, we saw our SQL Server steady state CPU utilization drop from 25% to 15%. That was a pretty big win for us. Additionally, moving the data and code to its own microservice gave us a great bounded context to work within as we go forward, keeping it isolated and making changes lower-risk and easier to deploy.
One thing that’s really easy to do during migrations is let “little changes” creep in. You see some code that could use a little cleanup, or find a data type or method signature that could be improved a bit, and it’s easy to say, “oh hey, I’ll just fix that now while I’m in there”. My advice: don’t. Every little change adds risk and additional testing to something that’s already inherently full of risk. Make a note of those things and change them after you’re done with the migration. Trust me, it’ll keep you sane.
We started the project without dedicated QA, and that really hurt us in the long run; we crammed a bunch of testing late in the effort. Try to get QA involved early and all the way through the process. On top of that, having good communication with our support team during the process helped us stay on top of any customer-facing issues that we didn’t notice with our metrics. Bottom line: don’t go too far off the grid. Being heads-down is important, but stay connected to keep the feedback coming.
Finally, make sure you’re monitoring everything you can. For us, that included things like:
- MongoDB operations
- CPU (and other system metrics) on webservers, SQL Server, and the new MongoDB systems
- User logins, accesses, updates, creates, etc. (for error rates, volume, and performance)
- Application logs (we use SumoLogic to aggregate), including many that we’d specifically added for the migration
It was an exciting, challenging (and at times grueling) project. I’m really proud of the team and all the time and effort put in to make it so successful. There’s so much more I could cover here, so if you’d like more detail or insight into something, hit us up on Twitter at @HudlEngineering.