Deploying in the Multiverse
At Hudl, we like to move quickly. We are constantly fixing issues, building new features, and improving the experience for our coaches and athletes. We put a lot of thought into how we work and dedicate a lot of time to making sure we are working as efficiently as we can. So, when we began to run into major bottlenecks in our deployment process, we realized we needed a major change. We came up with a plan to break our monolithic application into smaller components, and thus The Multiverse was born.
Deploying in the Multiverse
At Hudl, we like to move quickly. We are constantly fixing issues, building new features, and improving the experience for our coaches and athletes. We put a lot of thought into how we work and dedicate a lot of time to making sure we are working as efficiently as we can. So, when we began to run into major bottlenecks in our deployment process, we realized we needed a major change. We came up with a plan to break our monolithic application into smaller components, and thus The Multiverse was born.
This is the second in a two-part series about deploying code at Hudl. Part 1 was about deployment of our primary application, “The Monolith”. This part will talk about some of the lessons we’ve learned and how we’ve applied them to our multiple application framework “The Multiverse”.
At Hudl, we like to move quickly. We are constantly fixing issues, building new features, and improving the experience for our coaches and athletes. So we put a lot of thought into how we work and dedicate a lot of time to making sure we are working as efficiently as we can. Our product team is broken up into cross-functional squads consisting of one or two developers, a product manager, a quality analyst, and a designer. Each squad independently plans, prioritizes, develops, and ships features. We modeled this structure after Spotify’s product team (pdf) and adapted it to fit our culture. This structure has enabled us to very quickly improve our product and respond to user feedback.
Life Before the Multiverse
Up until January of 2014, all development for hudl.com took place in one repository, which is now lovingly referred to as “The Monolith”. This worked fine for us when we had a dozen or so squads. However, about a year and a half ago, we began to hit some bottlenecks.
At that point, the Monolith codebase was growing to the point of being unmanageable. Currently, it consists of over 50K commits and takes up more than 4GB of space on disk. Each deploy takes about 30 minutes if everything goes smoothly. When a squad wants to deploy, they have to wait in the deploy queue, which in some cases means their code won’t be pushed to prod for another few hours or maybe even the next day. This kind of bottleneck is unacceptable and is only going to get worse as we grow our team. To enable our squads to continue to move quickly, we decided that we needed to change.
Enter the Multiverse — A 40,000 Foot View
The Code
The Multiverse is Hudl’s microservices framework. While a lot of development still happens in the Monolith, we have begun to split up our codebase into smaller services. Each service has its own repo and can be built, tested, and deployed completely independently of the other services. Keeping with Conway’s Law each squad typically has its own service that it is responsible for, though any person can commit code to any repo.
It is worth noting that our microservices might more aptly be called microapplications. I say this because each service is capable of serving up and handling page requests alongside its inter-service communication. So any service can be the entry point for a web request. For example, if a user navigates to <a href="http://www.hudl.com/trends/basketball">http://www.hudl.com/trends/basketball</a>, that request will get routed to the basketball service. The basketball service may read from its database and serve the resulting html, or it may call other services to get the data needed for the request.
Communication
Each Multiverse service exposes a client that other services can use to access its data and functionality. Services discover and locate each other through Eureka, an open-source service registry made by Netflix. All inter-service communication is wrapped in Mjolnir commands which help to isolate service failures when they inevitably happen.
Deployment Process
Deployments in the Multiverse require coordination between many moving parts. The program responsible for all of that coordination is called Alyx3 (the third in our line of deployment-coordinating programs). From here on, I’ll refer to Alyx3 simply as Alyx. Alyx’s job is to make sure a branch gets from its first commit to serving its first production request safely and efficiently. To do this, it coordinates with Teamcity, Eureka, Github, Amazon SNS, Route53, and Outpost (more on that one later).
Branch Lifecycle
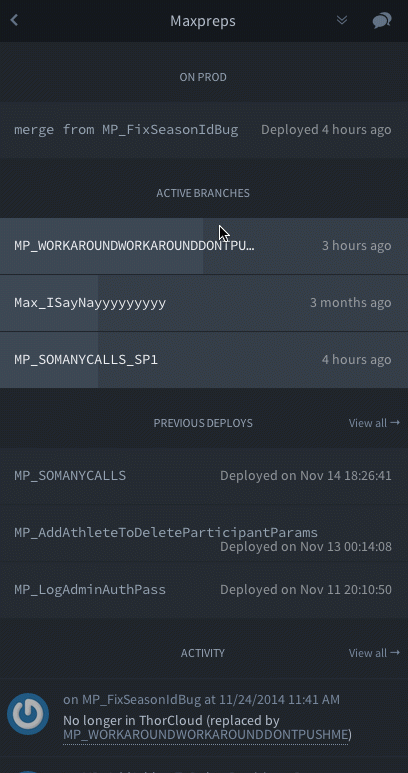
Branches first appear in Alyx when they are pushed up to Github. Alyx learns about the new branch via a Github webhook. After that point, the developer can freely add commits and deploy the branch to our testing or staging environment. As branches are developed and tested, Alyx shows their progress.
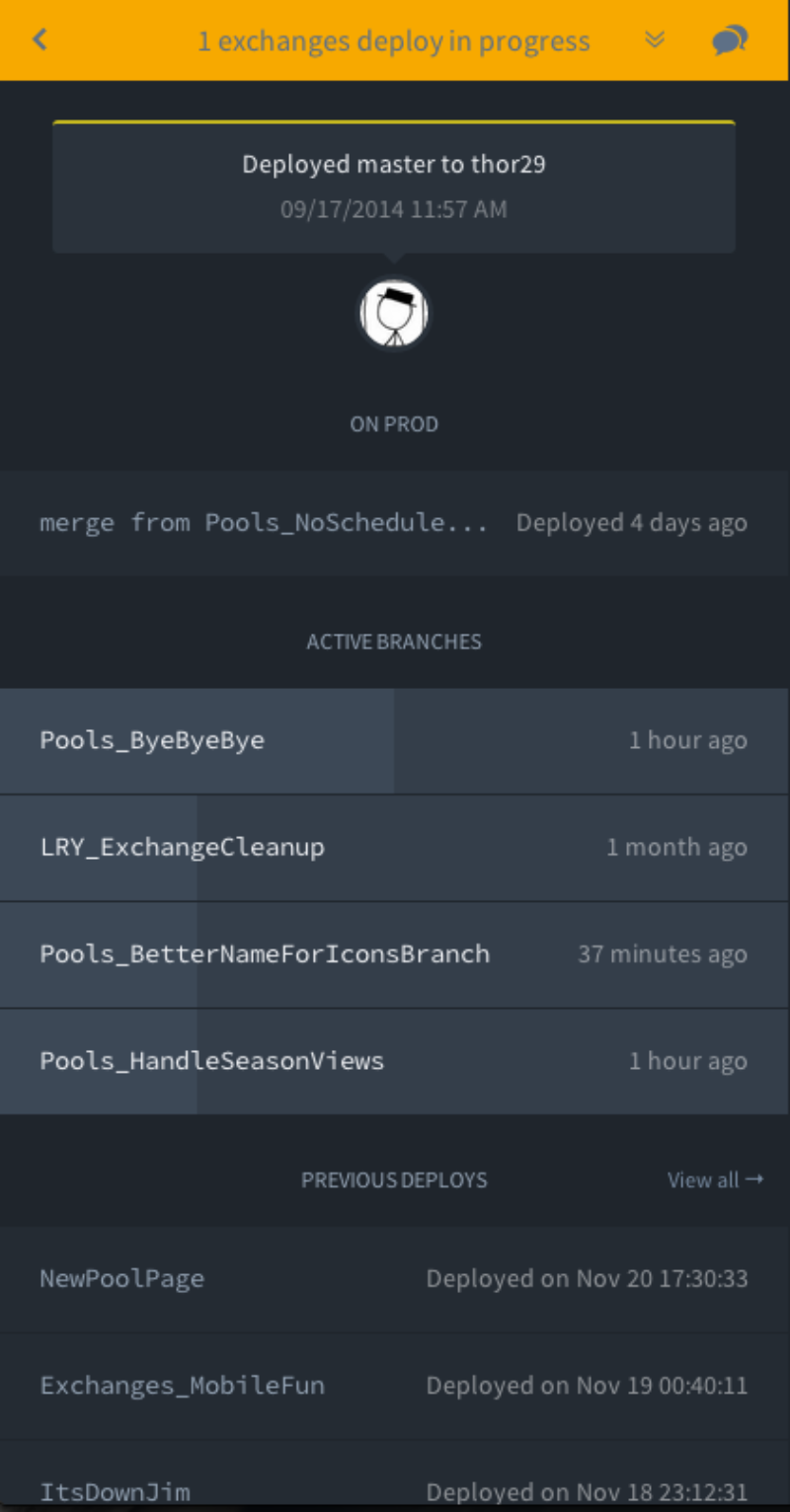
When a branch is merged into master, Alyx knows it is ready to deploy to production. The actual deploy begins when a squad member, typically the Quality Analyst, hits the “Deploy” button in Alyx.
If the deploy succeeds, the branch is archived so we can refer to it later and roll back if needed. This graph shows the entire lifecycle of a branch as it moves through Alyx:
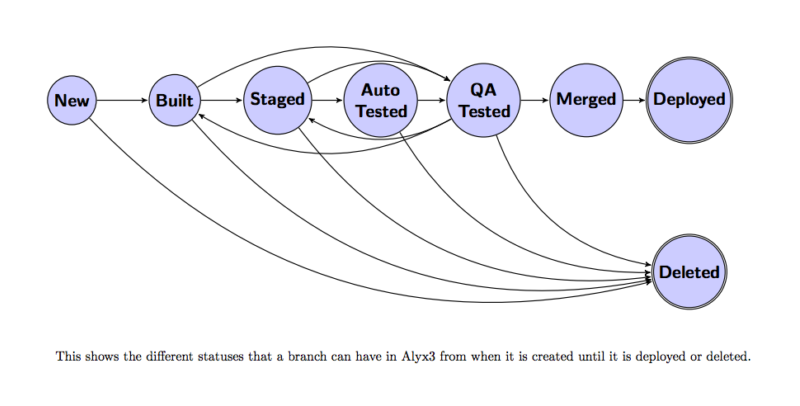
Deploy Lifecycle
Here is a somewhat simplified picture of what the process might look like for a typical deploy:
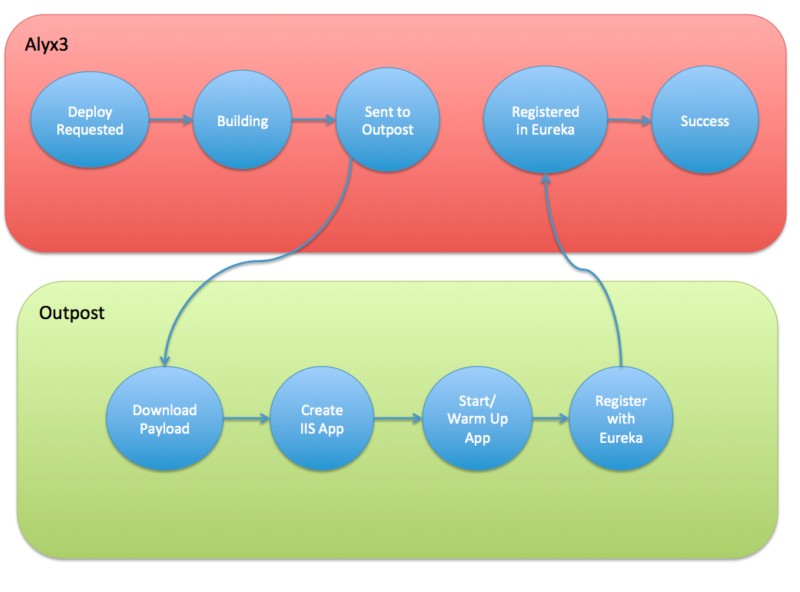
When the deploy is kicked off, Alyx checks with Github to make sure it knows what the latest commit on this branch is (which at this point is usually a merge into master). Once that is confirmed, Alyx asks Teamcity, “Do you have a build of branch ‘master’ at commit ‘efd32de’? If not, kick one off and let me know when it’s done.”
Once Alyx knows where the built payload can be downloaded from, it needs to figure out where the new bits need to be deployed to. If it’s being deployed to a test environment, Alyx will find a test machine that isn’t being used yet. If the branch is being deployed to production or stage, it will be going to all of the production/stage instances in the service’s cluster.
After figuring out what instances the deploy will target, Alyx sends a message to those machines through Amazon SNS. The message is something along the lines of “All prod servers in the basketball cluster, please deploy the payload from this URL. Register with Eureka after and let me know when you’re done.”
The program that reads and interprets these messages is called Outpost. Outpost is a very simple .NET app that runs on all our application servers. It has the sole purpose of receiving/interpreting SNS messages and then running the appropriate deploy scripts. While it is functionally very simple, Outpost is flexible enough that it is even capable of deploying new versions of itself.
The deployment scripts are PowerShell scripts that download the specified payload, unzip it, create/start the app in IIS, warm up the app, and instruct the app to register with Eureka. This entire process usually takes between one to two minutes. Once the script is complete, the app is ready to start taking traffic!
Meanwhile, Alyx is sitting and waiting for the deploy to complete. It is constantly monitoring Eureka to make sure the necessary servers get registered within a certain time frame. Additionally, each server regularly publishes its status to an SNS topic that Alyx is subscribed to. This makes it so Alyx can give granular status updates to whoever is waiting for the deploy to complete.
Results
We are still actively improving and developing our deployment system, but our preliminary results have been very promising. Here’s a snapshot from one of our dashboards that monitors the number of deploys we do:
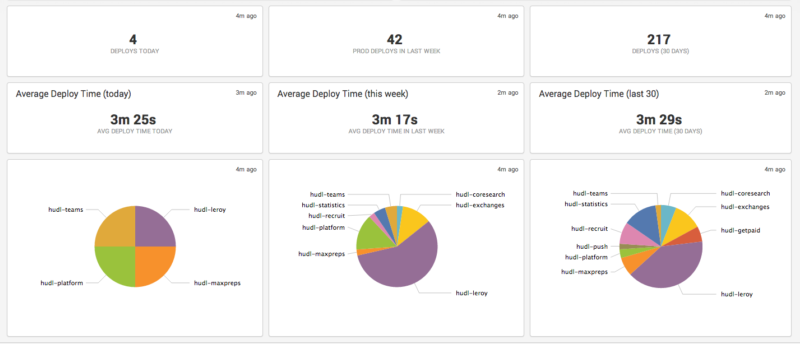
That just depicts Multiverse deploys. Because deploy times are shorter and can happen in parallel (each service can deploy independently) squads are able to deploy much more frequently.
SNS Takeaways
We use SNS fairly extensively in this process. One of the key takeaways we’ve learned is to never expect the messages to arrive in order or within a certain time frame. Usually the messages arrive within a few seconds, but the ordering of them can be arbitrary if the messages were sent shortly after one another.
Another takeaway for working with SNS is to split your communication up into multiple topics when possible. This makes it easier to ignore irrelevant messages and reduces the amount of application logic that you need to write just to differentiate different types of messages. We are currently using a single SNS topic for all messages that Alyx receives, but would ideally split it up to use a different topic for each message type.
Errors are normal
When deploying new code many times a day, it is inevitable that errors will happen. So, it is important to handle errors well and not assume that they are an exceptional case. With a program like Alyx, errors can occur in many different ways. Messages from Github may not get delivered, builds could get backed up in Teamcity, servers could unexpectedly stop their heartbeat to Eureka, etc. One thing we have learned about dealing with these sorts of failures is that transparency is key. The most important part of failure is to communicate that failure to your users. While it may be bad when errors happen, it is even worse when they go unnoticed.
Our deployment system does a fairly good job of recovering when issues arise. There is retry logic and fallback scenarios set up for the pieces that are known to fail from time to time. However, when automatic recovery fails, we try to get as much information to the users as possible. For example, if a deploy script spits out an error message, Outpost sends that message to Alyx so that it can be shown to the person who kicked off the deploy.
Looking Forward
Alyx (and our whole Multiverse deployment system) is still a work-in-progress. We are constantly working to improve the experience and performance for our squads. Thus far it has been a huge success for our Product Team and we’re excited for the next steps. If you are interested in working with us to solve the next set of hard problems, you should visit our jobs page. We’d love to hear from you.