Populating Fulla with SQL Data and Application Logs
This is the second in a series of posts on Fulla, Hudl’s data warehouse. This post discusses our methods to update Fulla daily with data from our production SQL databases and our application logs.
Populating Fulla with SQL Data and Application Logs
This is the second in a series of posts on Fulla, Hudl’s data warehouse. This post discusses our methods to update Fulla daily with data from our production SQL databases and our application logs.
This is the second post about Hudl’s internal data warehouse, Fulla. The first post introduced Fulla, discussed our desires in a data warehouse, and detailed our path to Fulla v2. This post will cover our ETL (extract-transform-load) pipeline to get Hudl’s production SQL and application log data into Fulla on a regular schedule.
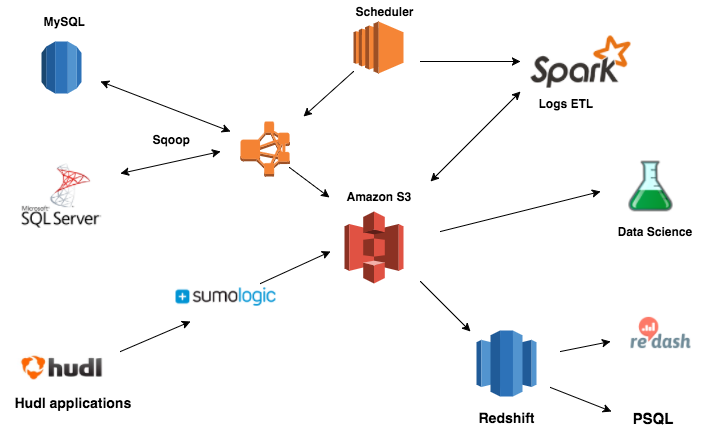
Production SQL Data
We have three major sources of data that go into Fulla. First, we have our production relational databases. We have two relational databases, one SQL Server and one MySQL. They are each about 100 GB, which makes this source easily the smallest of our three sources.
To keep Fulla in sync with our relational databases, we execute nightly batch jobs to refresh the data. For each database, we spin up an Elastic MapReduce (EMR) cluster to run a Sqoop job against a read replica. The data is saved in Avro format on S3. Once a table has been exported to S3, we truncate the table in Fulla and upload the newest data. Given the similarity between tables in SQL Server and MySQL and tables in Redshift, as well as the comparably small size of our relational databases, this has been the easiest part of our ETL pipeline.
Application Logs
Our second source of data is our logs. Hudl made a decision a while back to Log All the Things. As a result, we generate a few hundred million application log messages per day during our busy seasons. We recently moved to Sumo Logic (from Splunk) to collect and review our log data. Sumo Logic is great for real-time queries, but it slows down when doing multi-day queries over a broad set of logs. Further, Sumo Logic only stores data for the last 60 days, making it impossible to do year-over-year comparisons.
Sumo Logic sends rolling archives of our logs to an S3 bucket, so getting the raw data isn’t difficult. However, we don’t have strictly structured logs, so mapping an individual log onto a columnar database like Redshift is non-trivial. We decided to perform a few ETL steps before loading. First, we made the decision to keep only application logs and drop other logs (e.g. Nginx) for which the volume outweighed the utility. Second, we didn’t want to just load the raw log message to Redshift, as this would require significant regex parsing and substring extraction by Fulla users. To make it easier for Hudlies to query log messages, we decided to handle some initial parsing before loading into Redshift.
For example, a typical log message looks like the following:
2015-10-11 11:22:33,444 [INFO] [Audit] [request_id=c523a1e3] App=Hudl,Func=View,Op=Clip,Ip=6.10.16.23,AuthUser=12345,Team=555,Attributes=[Clip=4944337215,TimeMs=10]
It includes a timestamp, a hostname, log level, and a bunch of key-value pairs. Many of these key-value pairs are used in almost all log messages, such as App, Func, Op, and AuthUser. We analyzed a set of log messages to find the most commonly-used 100 key-value pairs. We then wrote a job using regex patterns for each of those key-value pairs to extract the keys and values from the message. We’ve also allowed users to request additional key-value pairs to parse out. Now, in addition to the common log values of time, host, and even the raw message, our logs table in Fulla has over 140 other columns that Hudlies can query. Wide tables aren’t a concern in Redshift. It’s a columnar database, so it only fetches the requested fields on reads rather than the entire row.
As an added benefit, it has been relatively easy to transition a query from Sumo Logic to Fulla. Hudlies are Sumo Logic power users, whether it’s someone from our awesome coach support team looking for an accidentally deleted playbook or a Product Manager checking the impact of a new feature. Rather than forcing them to memorize two ways of accessing data, they can use most of the same logic. This has been a strong factor in our quick adoption rate as over 180 Hudlies have signed up for Fulla, representing nearly half of all employees.
Lessons Learned
The transition to Fulla v2 has gone pretty well, and we’ve learned a lot along the way. Below are a few of our more helpful tips.
Automate, Automate, Automate.
The data in your data warehouse should update automatically, without someone needing to push a button. Your pipelines will need tweaking and require a fair bit of babysitting at first, but they will stabilize eventually. Think of the pieces that are shared across pipelines, and see how you can abstract them to be used in new pipelines.
For example, we have a script to launch an EMR cluster. You can specify a number of nodes, utilize spot pricing, and run any number of arbitrary jobs. To create a new job, you just need to use a defined format – have a run.sh script that will prepare your environment and run the job, then zip up the directory and post it to S3. Our scheduler spins up new clusters every night to run the jobs, and they terminate when they’re finished. This has made it really easy to add new components to our ETL pipeline and has saved us a lot of money by avoiding the use of long-running EMR clusters waiting for a task.
Use a Workflow Management tool
We make heavy use of Spotify’s Luigi in our pipelines. It is great for managing dependencies when executing long chains of tasks. Make sure you take full advantage of it by composing your jobs into the smallest unit that makes sense. For example, our Sqoop job on our SQL Server exports data from 80 different tables. Rather than do a single sqoop import-all task in Luigi, we do a sqoop import task for each of the 80 tables. If our spot instances get terminated after exporting 79 of 80 tables, we can quickly pick up where we left off rather than starting over at the beginning. Luigi sees that we’re only missing data in S3 for one of the tables, so it does a sqoop import on that table, then proceeds to cleaning and loading to Redshift.
There are a number of other workflow management tools out there, like Airbnb’s Airflow. Find one that works for you (or build your own, if you’re adventurous).
Know your data
As you’re putting together your data warehouse, it’s important to know how your data is stored and how your users will access it. This will come into play not just on SORTKEYS and DISTKEYS for Redshift, but in how your ETL pipeline is structured.
As one example, I noted that we truncate all the tables from our relational databases and load entirely fresh data in every morning. It’s possible to update tables from a relational database in Redshift without doing this, by updating only those rows that changed. We briefly discussed streaming the binary log from MySQL and the transaction log from SQL Server, saving the updates to a staging table, and merging on a more frequent basis. However, we ultimately decided this wasn’t worth the engineering time. Our relational databases are not that big, and they don’t contain our most frequently requested data. Running the Sqoop job and copying the data into Redshift takes about 2 hours with a 5 node EMR cluster. This ends up costing us less than $3 per day, as we use spot instances with ephemeral EMR clusters.
Our third post will discuss our initial performance issues with our design and the steps we took to improve the Fulla experience for our users.