
Benefits of Exposing Data Through GraphQL
GraphQL is rapidly growing in popularity within our organization at Hudl. Although we have only been using GraphQL for a few months, we are already reaping the benefits of it.
Benefits of Exposing Data Through GraphQL
GraphQL is rapidly growing in popularity within our organization at Hudl. Although we have only been using GraphQL for a few months, we are already reaping the benefits of it.
GraphQL is rapidly growing and proving itself to be a reliable replacement for REST. Since Facebook has released GraphQL, other companies such as Twitter and Intuit have created GraphQL implementations for their APIs. For those who aren’t familiar, GraphQL is a query language and type system used to help solve some major pain points of REST: keeping updated API documentation, infinite endpoint management, and ever-growing payloads. GraphQL is rapidly growing in popularity within our organization at Hudl. Although we have only been using GraphQL for a few months, we are already reaping the benefits of it.
Combining and Querying Data
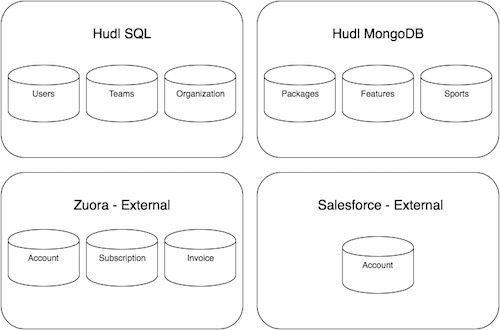
On my team Hudl, we are tasked with building tools for users (external and internal) to sign up, invoice customers, track revenue, and manage customer accounts. The biggest concern for our team is data integrity among numerous external sources. Our support team is working inside of an internal admin site, sales team is working with Salesforce, account management with Zuora, and business development team with Netsuite. Several times a day, these sources can be updated and we have to ensure ever-changing data is continually in sync among all of these dependencies. While managing all of this outside data, we also have to be conscientious about maintaining relationships in our own SQL tables and MongoDB collections.
So we have a lot of data — but why does that matter for GraphQL? Our teams at Hudl are all running their own microservices, and we have to ensure this data is consumable by our own client and other backend services. By using GraphQL, we only have to manage one route and one schema for all of our data. As we populate this advanced schema from different data sources, GraphiQL (Facebook’s in-browser IDE for exploring schemas) effectively generates API documentation for our consumers, and prevents us from spending precious coding time on documentation.
Combining and Querying Data
A great improvement that GraphQL provides us with is the ability to use a common query language amongst several different sources of data. We can access, modify, and query all of the tables below (and more!) in a single GraphQL call, reducing the number of touchpoints and latencies for the consumer.
Importance of Caching
When you’re able to combine all of these sources of data, it’s easy for your queries and mutations to give poor performance. For our external dependencies, it’s common to see 100 – 200ms latencies on every request we send. Some mutations and queries may require 10 – 15 requests to various endpoints. These long delays highlight the need for an effective caching layer. This means you have to evaluate the importance of every data source in each query and mutation.
Picking Your Payload
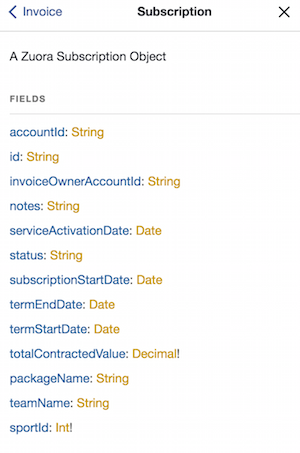
Another benefit of GraphQL is the consumer controlled payload sizes. The consumers of this data can choose which specific values they wish to retrieve. Consider the invoice object below shown in GraphQL below:

It might make sense on a billing page to serialize and display all of the information above about a customer’s invoice. Although, if a consumer wanted to check the name of a package, we wouldn’t want to have to return all of the data that’s useless to them. The consumer can choose to receive only the fields they desire, which prevents extra serialization. Consumers get to bask over small performance gains, and we get to rejoice; realizing that we don’t need to write another REST endpoint to handle separate payloads.

Front-end clients see even more benefit from choosing their own payloads. With GraphQL, we can simplify the work needed to stand up a new page that requires a different subset of data from our schema. No new model creation or route configuration is necessary on the backend. You just send a request to the same GraphQL endpoint with different query parameters. We use Lokka on our team to do this, which is a simple JavaScript client for interacting with GraphQL.
Wrap-Up
We’ve seen a lot of benefit by exposing all of our APIs through GraphQL. As developers, we spend less time worrying about API documentation. Any consumers are able pick specific payloads from complicated data objects. Our front-end is able to interact with all of our data sources through one common query language. Even though we have lots of external dependencies, through efficient caching we have seen respectable performance and have written much more maintainable code. If you haven’t started using GraphQL yet, I’d urge you to at least try it out.